国服开发杂谈
-
starmie为什么是神
-
听我说谢谢你 四大麦
-
四大买我的超人
-
我们修改这个对象的onTournamentEnd()方法
用B类的静态方法替换A类的某个实例的动态方法,这是不守面向对象基本法的,只能在无法无天的脚本语言里实现。国服里还有两处这样的实现,分别是Ladder和Battle类。这种做法其实是上不得台面的,在类型安全和垃圾回收上可能有各种各样的问题。但有一点好处无法替代,就是不需要改动A类的代码。所以这是在二次开发中由于原作者没有留好接口,不得已而为之的。
但今天我老板给我推销这个。背景是我手上有一个项目算是基于PyTorch的二次开发,这样做不仅我这边写着方便,而且对于用户来说也更傻瓜了。但这可是开源项目啊,是要我把法外狂徒四个字贴贵司脸上吗?
当然,这不重要。只要能省我两小时工作量,我就觉得他是这个👍。你说上不得台面?不不不,这反而是高端技巧!要有道路自信,让那群老古董们颤抖吧!
-
Pokemon Showdown 结构概要 上
上周给国服升级了https,借这个机会讲一下PS整体结构。这篇文章将帮助你理解:当你使用PS时,你的浏览器里发生了什么,你的网卡上发生了什么,对应的PS服务器上又发生了什么。
0. 我奶奶都能听懂的计算机网络导论
- 简化了很多内容,因此会多处表述不严谨,而且我只讲我需要讲的
- 每台机器连接到公网后会有一个IPV4地址,比如国服服务器的IPV4地址就是 47.94.147.145
- 每台机器有很多个端口,机器上运行的程序(服务)可以监听一个或多个端口,比如国服论坛就通过 80 端口接收用户发来的数据,那么国服论坛这个程序的地址就是 47.94.147.145:80
- 当你访问某个网站时,你的机器会从某个随机端口向该网站的服务器发送一些IP数据包,然后服务器会给你回复另一些IP数据包
- IP数据包里面有TCP数据包,TCP数据包里面有HTTP数据包或WebSocket数据包
- 使用HTTP协议访问网站时会默认走80端口,所以这个80是可以缺省的,只有当你访问的不是80端口时才需要指定,比如国服测试服:47.94.147.145:8000
- 有一种服务器叫做域名服务器(DNS),当你使用域名访问某个网站时,会先从域名服务器拿到这个网站的IP地址和端口,比如 *.one 的域名服务器就会把 pschina.one 解析到 47.94.147.145:80
- 你的浏览器是一个JS运行环境,当它访问某个网站时会根据其设置拿到一些前端(client)代码,使用这些代码绘制网页内容,并和后端(server)通信,这里的后端指的是和业务相关的服务器
- 前端会在你的浏览器里记录一些用户数据,这个叫做Cookies,比如你的队伍库就保存在Cookies里
- 我们主要介绍中心式的服务结构:每个用户的浏览器上都有一套前端代码,而它们要访问的后端只有一套,但这一套后端可以分布在多个IP地址和端口上分别负责不同的功能
- HTTPS的意思是“加密的HTTP”,其加密原理是网站把自己的RSA公钥上传到某个公认的中间商,用户使用从中间商拿到的公钥加密自己发给网站的数据,网站服务器收到后使用私钥解密
- 使用HTTPS协议访问网站时会默认走443端口
1. play.pokemonshowdown.com
- 这是获取PS公用前端的地址,同时是公用账号服务器(login server)
- pokemonshowdown.com(104.22.63.197)是PS的主页,也是PS自己的域名服务器,它会把 play.pokemonshowdown.com 解析到 172.67.4.23
- psim.us (104.22.11.234)也是PS自己的域名服务器,它会把各个子服务器(*.psim.us)解析到对应的地址,比如把 china.psim.us 解析到 39.96.50.192
- 当你访问 play.pokemonshowdown.com 时,前端会和默认后端 sim2.psim.us(104.22.11.234) 通信,这个就是官服
- 当你访问 xxx.psim.us 时,浏览器会先去 play.pokemonshowdow.com 获取前端资源,再和指定后端 xxx.psim.us 通信
- 你的账号和密码也保存在 play.pokemonshowdown.com,这时它作为账号服务器,无论你在官服国服还是比赛服,账号的登入登出都是和它通信确认的
- Replay 都保存在公用回放服务器(login server)replay.pokemonshowdown.com 上,它的IP地址也是 172.67.4.23,当然这不一定是一台机器,很有可能是一个集群的入口
- 当且仅当使用PS公用前端时才可以访问公用账号服务器和公用回放服务器
- PS前端和账号服务器的代码也是开源的,Github仓库分别是 https://github.com/smogon/pokemon-showdown-client 和 https://github.com/smogon/pokemon-showdown-loginserver
(未完待续)
-
不过CPU里并没有这个数1的电路,得用移位来做
这两天更新队伍数据库,又看到这段移位数 1 的代码:
let simVal = 0; for (let j = 0; j < teamCodeLength; j++) { const simCode = teamCode[j] & targetTeamCode[j]; for (let x = simCode; x > 0; x >>= 1) { simVal += x & 1; } }对每一个 32 位的
simCode它都最多需要循环高达 32 次,让我觉得CPU很累,想给它减负。但短暂思考后没有好的思路,在认识到我并没有比去年的自己更聪明之后,决定试一下来自FPGA的馊主意:查表!具体来说就是,直接把
simCode的所有可能值对应的 1 的个数存下来,计算simVal时直接查就可以了。当然我存不下 32 位(43 亿)的表,但 4 位(16)或者 8 位(256)还是可以的嘛!这样至少不用每次只移一位了:const simValLUT = [ 0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4, ]; let simVal = 0; for (let j = 0; j < teamCodeLength; j++) { const simCode = teamCode[j] & targetTeamCode[j]; for (let x = simCode; x > 0; x >>= 4) { simVal += simValLUT[x & 15]; } }这样改完之后一测试,居然变慢了,查表是个负优化!当然这也并不奇怪,因为和FPGA的硬件LUT不同,这个
simValLUT是在内存里的,而相对访问寄存器和做位运算来说,访问内存是一件很慢的事。当然现代CPU单核可以有64KB的一级缓存,所以在遍历队伍库的过程中这个simValLUT被读取一次之后就被备份在一级缓存里了,而且碰撞率很高。但访问一次一级缓存也需要 4 个CPU时钟周期,在移位上省下来的时间就这样又被花出去了。但我不甘心,还是想把这个丑陋的移位算法干掉。于是今天我灵机一动去问了New Bing:
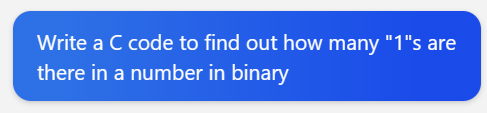
它先是给出了一个一模一样的移位算法:

我寻思这是把我当小学生呢,继续刁难它:

终于大的来了:
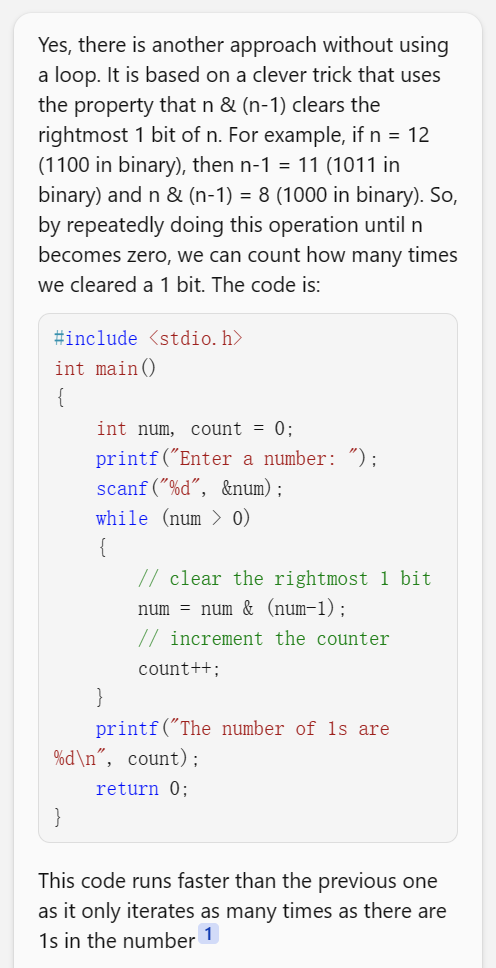
它并没有按我的要求删除循环,但确实变快了很多。让我们翻译一下:let simVal = 0; for (let j = 0; j < teamCodeLength; j++) { const simCode = teamCode[j] & targetTeamCode[j]; for (let x = simCode; x > 0; x &= x - 1) { simVal++; } }看似只改了一点,但是这样处理一个 32 位的
simCode最多只需要循环 6 次,而且处理一组 5 个的teamCode最多只需要运算 5 + 6 = 11 次,这是十倍的优化!细说原理:
x &= x - 1可以将x的最后一个 1 变成 0,因为减法借位只影响最后一个 1 及之后的数。比如:1011100 // 92 & 1011011 // 92 - 1 = 91 ---------- 1011000 // 88 = 92 - 4: 倒数第三位 1 变成了 0正如New Bing所说,新算法的迭代次数和 1 的个数是相等的。而受限于队伍长度,一组
simCode最多只包含 6 个 1,x &= x - 1在这个场景的下降速度是飞快的。感谢New Bing,现在我们有了新的美妙的队伍数据库查询算法,查询速度提升到 1 毫秒以内啦!
-
@Starmie 这东西就是以前那个树状数组的lowbit(x) = x&(-x) 获得最低一位的1...我看到这个需求第一反应就是这个函数
然后如果是c++的话可以考虑一下stl里面的bitset,原理大概就是这东西是把32个连续的位压缩成int,对两个位组作逻辑运算的复杂度会除一个32的常数,里面有count()方法,可以试试看
不过这东西是不是负优化还不好说
edit:晚上回去我试试 -
@xujing691691 JS没法操作内存,我甚至没法确定这五个数字在内存里是连续的orz
但确实可以试试用C/C++写一套外置的队伍数据库,但这样维护起来就很恶心了
另外JS的内置number类很神奇,我也不知道是怎么实现的
edit: 发现一个叫做Uint32Array的东西,这个应该是连续的了 -
@Starmie
突然发现npm里面有个bitset包(这不巧了吗.jpg)然后研究了一下实验数据:随便取了一个32位含有6个1的数字
记录两个时间,分别是不用这个类的老方法(&=(x-1))、和拿已经预处理好的Bitset算的时间
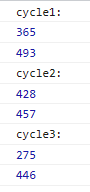
看起来好像还是直接干拔快
然后我去简单看了一下这个包的源代码


然后我想看看这东西是咋实现的,简单又翻了翻源码,发现了个函数
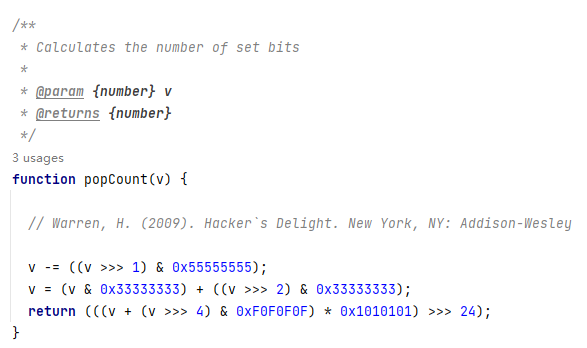
容易发现这个方法的时间复杂度是固定的,在稀疏下的场合应用不怎么好,但是很稳定,然后我试了一下1多的场合,这个方法明显比上面的按位减快很多,但是有一个问题是这个方法还是不够优,毕竟这个乘法看着很吓人
鸽了
edit:前面一边试队伍一边写的自己逻辑都看不下去...精简了下语言
edit2: https://zhuanlan.zhihu.com/p/341488123
这里面讲的比较详细,其中好像没有那个大乘法,所以那个乘法为什么会跑的效率还行呢...搞不明白
edit3:
我错了,我忘了vue里面调用方法的效率奇低无比

随便找了一下知乎的这个算法,看了一下时间
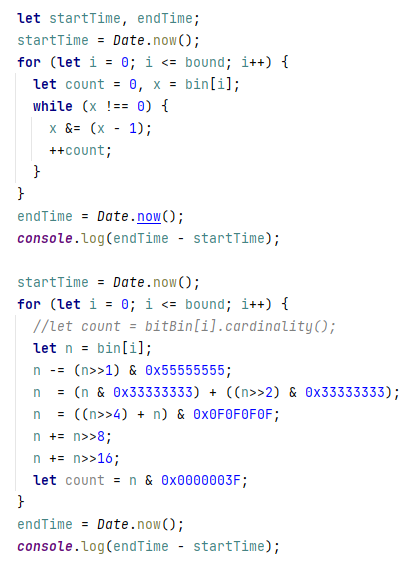
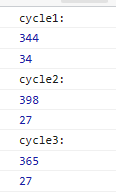
按位&的问题是计数器的加法和x的判空不得不忽略,这样导致开销远大于大量移位和&的算法
-
美妙のspeed